
According to the current analysis of Reports and Data, the IaaS market was valued at USD 75.0 Billion and is expected to reach USD 238.87 Billion by the year 2026, at a CAGR of 18%. The factors driving the IaaS market are a growing need for reducing physical infrastructure and save IT cost, technological advancements in Edge computing, and the increasing number of SMEs creating revenue opportunities for cloud IaaS providers.
Providing a powerful, self-service IaaS cloud can be a game-changer for many enterprise companies. By selecting the right technologies, you can transform your entire organization to an agile and high-performing business.
Building a large scale IaaS: The process
Building IaaS is a complex process, which requires careful planning. The final result in terms of reliability, performance and security is dependent on the initial preparation.
When you need to build an IaaS, you first need to answer some questions:
- What is the workload
- What capacity to start with and how to scale
- What hardware and storage to use
- What cloud orchestration system to use
- How to manage and operate the entire cloud infrastructure
Building a Large-Scale IaaS: The Challenges
There are multiple challenges that are encountered in almost every cloud/IaaS project. Below we present a short overview of which are the biggest challenges when building an Infrastructure as a service.
Reliability
With the scale the requirements for the reliability increases. At the same time, it is more difficult to achieve a certain level of reliability. The larger the infrastructure is, the more complex it is and the more components there are in the critical path. Achieving reliability becomes more difficult.
Complexity
Increasing the size leads to increased complexity. This applies to all elements – compute nodes, network, storage, orchestration, and monitoring. For example, on a small scale, you can put everything in one rack and a pair of top-of-rack switches will do a perfect job. With a larger scale, you need to build a complex network that can provide reliable and high-bandwidth communication between racks on multiple rows or even rooms in the data center.
Costs
One of the main goals of large-scale infrastructures is to reduce the operating costs per delivered resource. However, due to the increased requirements and complexity, the hardware and software costs can be very high. You shall consider both the initial cost and the recurring and upgrade costs.
Limited scalability
Every solution has limits. But many solutions have limits that are below the required scale for efficient operations. This can cause at least non-optimal operation and increased overall cost, but sometimes it can be prohibitive for some use cases. You have to select a solution that has enough scalability for the given task.
Low performance
In the ideal case, the performance of a system shall scale linearly with the size. In many cases, this can not be achieved which leads to insufficient performance for large-scale systems. The typical reasons for the limited performance are bottlenecks in the network, storage, and orchestration systems.
Lack of multi-stack support
When building a large scale system, it is important that the infrastructure will support all the required software stacks. It’s not optimal to build one cloud for Linux workloads and a separate one for Windows. Multi-stack support means not only multiple types of guests but also multiple different hypervisors – KVM, Xen, Hyper-V, VMware. Sometimes this requirement comes from a number of legacy applications that need to be supported, but sometimes this could be a requirement coming from a specific workload.
Vendor lock-in
Vendor lock-in is a problem for any scale. But in large scale infrastructures, this could be a really serious financial problem. As it is related to large investments in hardware, software, and staff.
Hardware refresh cycles
Something often overlooked is the hardware refresh cycle. It’s important that after a few years of operation the systems will allow the hardware to be replaced gradually, and not require complete system replacement introducing increased cost, operational complexity, and possibly downtime.
Also, not all parts of the system have the same lifetime – a typical example are the traditional storage systems when the old system could be still completely usable, but there is no feasible option to upgrade it. This requires replacing the entire storage with the next generation product and decommissioning the old system. The ideal solution will allow mixing different generations of hardware in the same system. Allowing the old components to be gradually retired when they are no longer economically viable and don’t force decommission equipment that still can generate revenue.
Also about the refresh cycle – think of it not only at a system level, but also at individual components – for example, does your storage system allow using the latest generation of drives available on the market in the old chassis? Or does it allow using the existing drives from the old system into the brand new one?
Why build IaaS with CloudStack?
Every cloud orchestrator has pros and cons and addresses the challenges we discussed before in a different way. There is no single solution perfect for all cases. But the features and capabilities of CloudStack make it a good fit for many large scale IasS projects.
First, it is an integrated product specially designed for IaaS. This makes it simple to deploy and operate, while at the same time provides all the functions that a typical IaaS operator needs.
The most popular alternative – OpenStack is not a specific product, but an ecosystem of different projects that can be combined to build a system for the specific use case. This makes every deployment unique and the implementation project very difficult. In contrast deployment of a CloudStack orchestrator is a straight-forward process and even the simplest deployment with out-of-the-box features is completely adequate for production use.
CloudStack can orchestrate simultaneously a broad range of hypervisors. The most popular is KVM, but there are also XenServer, VMware vSphere, and Microsoft Hyper-V. Also CloudStack supports bare metal hosts and LXC containers. With this, you can have one cloud that can cover all types of workloads that you may have.
CloudStack is designed to operate in large scale infrastructures. This diagram is familiar to many of you. This is the hierarchy of the resources in CloudStack. It is built with the concept of a hierarchical structure of zones, pods, clusters, and hosts.
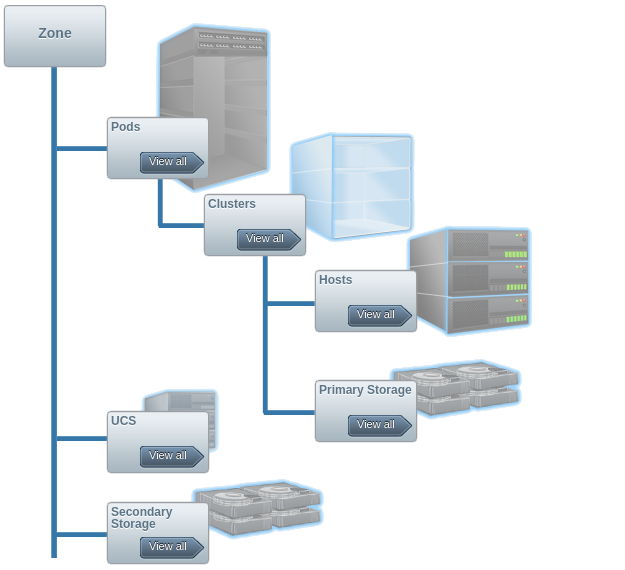
The controller is highly efficient and capable to manage thousands of hosts. It supports load balancing of the management tasks between multiple management nodes for very large deployments.
CloudStack supports high-availability at multiple levels. There is automatic failover for virtual machines, for the system resources, for the management server with load balancing, and so on.
CloudStack comes with a ready to use administration and end-user web interface, with a command-line interface, and with a very rich REST-based API that allows building sophisticated integration with third-party systems and automation of many tasks.
Because CloudStack is built as an integrated and high-performance product, the implementation is much simpler than alternative solutions at the same scale. This results in lower implementation and operating costs. The easy integration allows fast and flexible automation that is crucial for large-scale projects and can lead to a significant cut in the operating costs.
And last but not least – CloudStack is open source with constant development and a very active community. It’s a community-driven project, which means that its development is focused on the actual needs of the users.
Why building IaaS with software-defined storage?

While not all software-defined storage systems are equal, many of them provide features that make them a preferred solution for large clouds. When you’re looking for a solution pay attention if it can provide all the features that you’ll need.
Some SDS are built as a centralized controller with attached disk arrays. They operate in general in a similar way as a traditional SAN storages. They usually have limited performance and are not able to scale well. But many modern SDS solutions are distributed and some are built on “shared-nothing” architecture that allows them to scale very well both in terms of capacity and performance.
The distributed architecture also means better reliability and even more important, greater flexibility for the operation and maintenance. Distributed systems allow uninterrupted operation during maintenance. You can stop only part of the system for maintenance, while the full functionality is preserved, possibly with some reduction of the performance. This way you can do in-service software upgrades on even hardware refresh cycles, without one second of downtime. This not only eliminates one of the main sources of downtime but significantly simplifies the operations that can be another source of human errors, leading to more downtime.
The ability to scale easily the storage system at any time allows for more precise planning – you don’t need to plan the hardware for months or even years ahead as with the traditional SAN-based storage systems. Better utilization of the hardware means reduced hardware costs and reduced operating expenses.
Another great advantage is the vendor independence. There are several things here. First, you can use the hardware from your preferred vendor, and select from a wide variety of servers and components that best fit the task and get the best possible price. But more importantly, you are not locked-in to the same vendor once you buy something. You can always take advantage of the fair prices and the latest technologies available on the market.
Amito Building IaaS with CloudStack and StorPool

The UK-based leading MSP Amito built a large-scale multi-terabyte data storage platform with StorPool and CloudStack. Тhe storage solution spread across multiple clusters will support the enterprise-grade needs of Amito’s customers and will ensure a reliable data storage platform for their growing infrastructure.
Amito’s senior team has been working in the hosting sector for an average of 15 years each. Without a doubt, the most difficult part of the infrastructure stack for high availability virtualized servers is storage. The storage solution they were using wasn’t as strong as the rest of the platform.
Learn more: Amito’s implementation of IaaS with CloudStack and StorPool.
StorPool’s Integration with CloudStack
The following description of StorPool’s CloudStack storage integration applies to the KVM hypervisor, which is the most common case.
StorPool storage driver for CloudStack allows the StorPool storage to be fully managed by the CloudStack controller, eliminating the need for the operators to manually administer the storage system, like creating and deleting volumes, resizing volumes, attaching volumes to hypervisors, and so on.
Below you see a simplified diagram of a cloud build of CloudStack orchestrator, KVM hosts, and StorPool storage. Some components, like virtual network, are skipped for clarity. You can see the storage cluster at the bottom, in green, build of multiple Linux nodes. KVM hosts are at the top, and here on the right-hand side, we have a CloudStack management server.
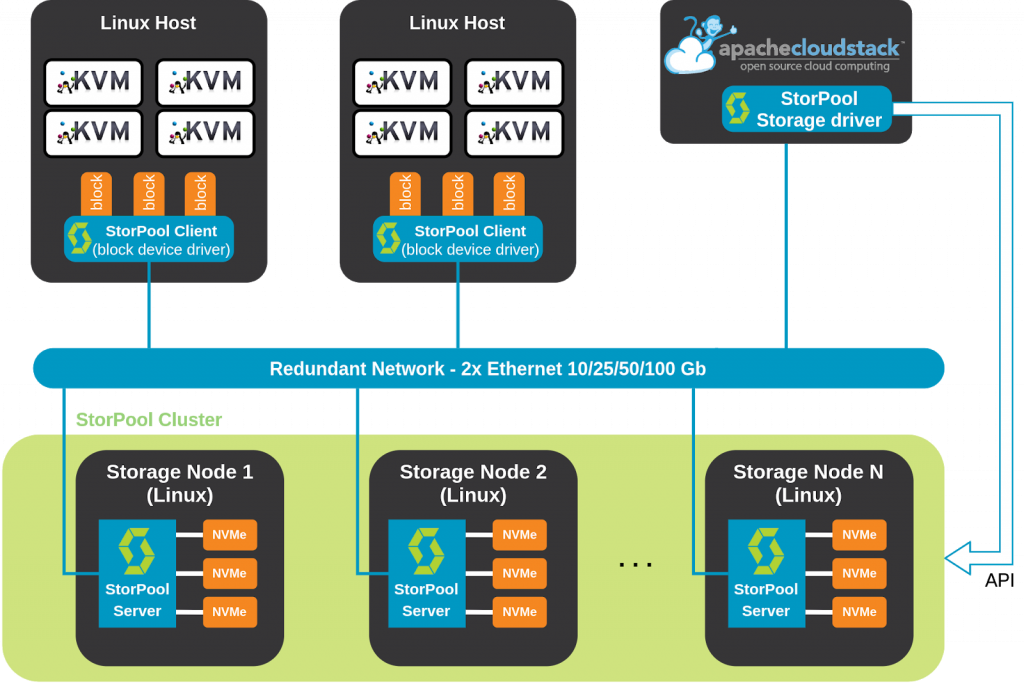
The integration between StorPool and CloudStack is built of two components. The first one is a StorPool client or the StorPool Linux driver. It’s installed on every KVM host. It provides Linux hosts direct access to the storage. With this driver, any volume in the StorPool storage system can be accessed as a regular Linux block device on the host, much like a local disk. If you are familiar with Ceph, it performs a function similar to the RBD driver.
The second component is a StorPool datastore driver for CloudStack. It is installed on the CloudStack management server and enables the CloudStack controller to manage the storage system and to perform all required tasks on demand – like creating, deleting, and resizing volumes, taking snapshots, etc.
Advantages of Using CloudStack with StorPool
Having a deep level of integration between CloudStack and StorPool allows taking advantage of many features of the storage system. Using the StorPool driver, many of the functions of the hypervisors are offloaded to the storage system, allowing better efficiency and reliability.
To enable this, the storage driver creates one volume per virtual disk and per image. This way many of the functions applied at a virtual disk level, that traditionally are executed on the hypervisors, can now be moved to the storage system. Such are taking snapshots, cloning images to create virtual disks, creating backups, applying QoS policy, and so on.
When a new virtual machine is created, the CloudStack controller is using the storage driver to create a volume in the storage system for each virtual disk. The driver also offloads the coping of the image into the virtual machine’s root disk to be performed directly by the storage system. This eliminates the need for the data to be transferred twice between the storage and the hypervisor. And because this is done now into the storage system it can do it in a very efficient way – it performs a copy-on-write clone of the image.
This implementation has two more advantages:
Firstly, the operation is instantaneous – no matter how big the image is, the creation of the virtual disk is completed in milliseconds.
Secondly and more importantly, by using copy-on-write clones, the created volumes don’t consume space on the storage system for the data that is cloned. This means that if you have hundreds of virtual machines created from the same template, there will be only one copy of all the common files, to be stored on the primary storage. This provides significant space-saving and reduces both Capex and Opex.
Another example of efficient offloading of functions to the storage system is snapshots. The traditional implementation of snapshots is using qemu process on the hypervisor to take the snapshot. With the StorPool integration snapshots are performed directly on the storage system. This not only offloads the hypervisor from this task but also enables the snapshots to be stored very efficiently on the storage system. Snapshots in StorPool are also implemented using copy-on-write. This makes taking a snapshot a very cheap operation – both in terms of CPU, bandwidth, and storage space.
StorPool’s CloudStack Integration Features
Group Snapshots
StorPool driver for CloudStack provides a unique feature of group snapshots. With this feature snapshots of all disks of a virtual machine are done as an atomic operation. This means all snapshots are created at exactly the same point in time and the data across all disks is consistent. This is especially important for applications such as databases, or applications with cache or data structures stored on multiple disks.
Disaster Recovery
StorPool’ s CloudStack storage has some built-in features that facilitate building disaster recovery infrastructures. Using these features you can build a DR cloud or DR zone in the same cloud, where you can keep copies of your running virtual machines. If the main site goes down, you can spin off the virtual machines in the DR center directly from the storage system there, without the need to recover from backups. This greatly reduces service recovery time and increases the total availability of the system.
Automatic Backups
StorPool storage also includes automatic backup functions. Automatic backup is based on snapshots and can store backups on the same storage or on a remote one. With this feature, you can define different backup and retention policies and select volumes to be backed up by multiple criteria. This function is completely transparent to the upper layers and end-users, but it can be integrated with higher-level systems using simple commands.
Eliminate the Secondary Storage
Secondary storage is typically used for storing backups and snapshots. Both of these functions are handled very efficiently by StorPool. Snapshots are stored very efficiently on the same or on a remote storage. Backups can be performed directly by the storage system with efficiently storing the common data saving network bandwidth and storage space. This eliminates the need for a secondary storage. With StorPool, the secondary storage in CloudStack is optional. This can save both Capex and Opex.
This is an example of how using a capable, feature-rich storage system with a well-implemented integration allows you to simplify the design of the entire cloud and to simplify the operations while enabling new services for your users.
Use cases
To wrap up, the combination of CloudStack and StorPool is suitable for may use cases where high-availability, high-performance, and high scalability are required.
The typical are:
- Public clouds
- IaaS
- Private and hybrid clouds
- DevOps automation
- Building Kubernetes clusters or Kubernetes-as-a-Service in an existing virtualized environment. This uses the new feature “Kubernetes Service” introduced in the latest 4.14 release.