Fast Kubernetes Persistent Storage
StorPool provides fast and reliable persistent storage / persistent volumes for large bare-metal Kubernetes Clusters through its Kubernetes CSI driver
High-Performance Block Storage for Kubernetes
When deploying containers with Kubernetes or containerized applications, companies eventually realize that they need persistent storage. They need to provide fast and reliable storage for databases and other data used by the containers.
StorPool, a leading software-defined storage platform, is integrated with Kubernetes via CSI (Container Storage Interface). Any company can easily deploy applications and microservices in containers and ensure their performance, scalability, and availability with Storpool fast and reliable storage for Kubernetes.
StorPool’s Integration with Kubernetes
StorPool provides persistent volumes for Kubernetes, through a K8S CSI driver.
StorPool’s Kubernetes CSI allows K8S to create volumes and use the storage provided by StorPool’s cluster to store persistent volumes. This can be used as a default for all data, not only databases or stateful applications/microservices.
There are three ways to deploy Kubernetes at the moment:
- The first is to use bare-metal nodes for K8S, where the StorPool CSI driver will be used.
- The second is to use virtual machine instances for the Kubernetes nodes. In this case you will not need the StorPool-Kubernetes integration. And you can still use StorPool with the underlying virtualization platform (for example OpenStack).
- The third is to run K8S in Public cloud, say AWS/GCP/Azure/etc. In this case you would typically use the native block storage service of the public cloud.
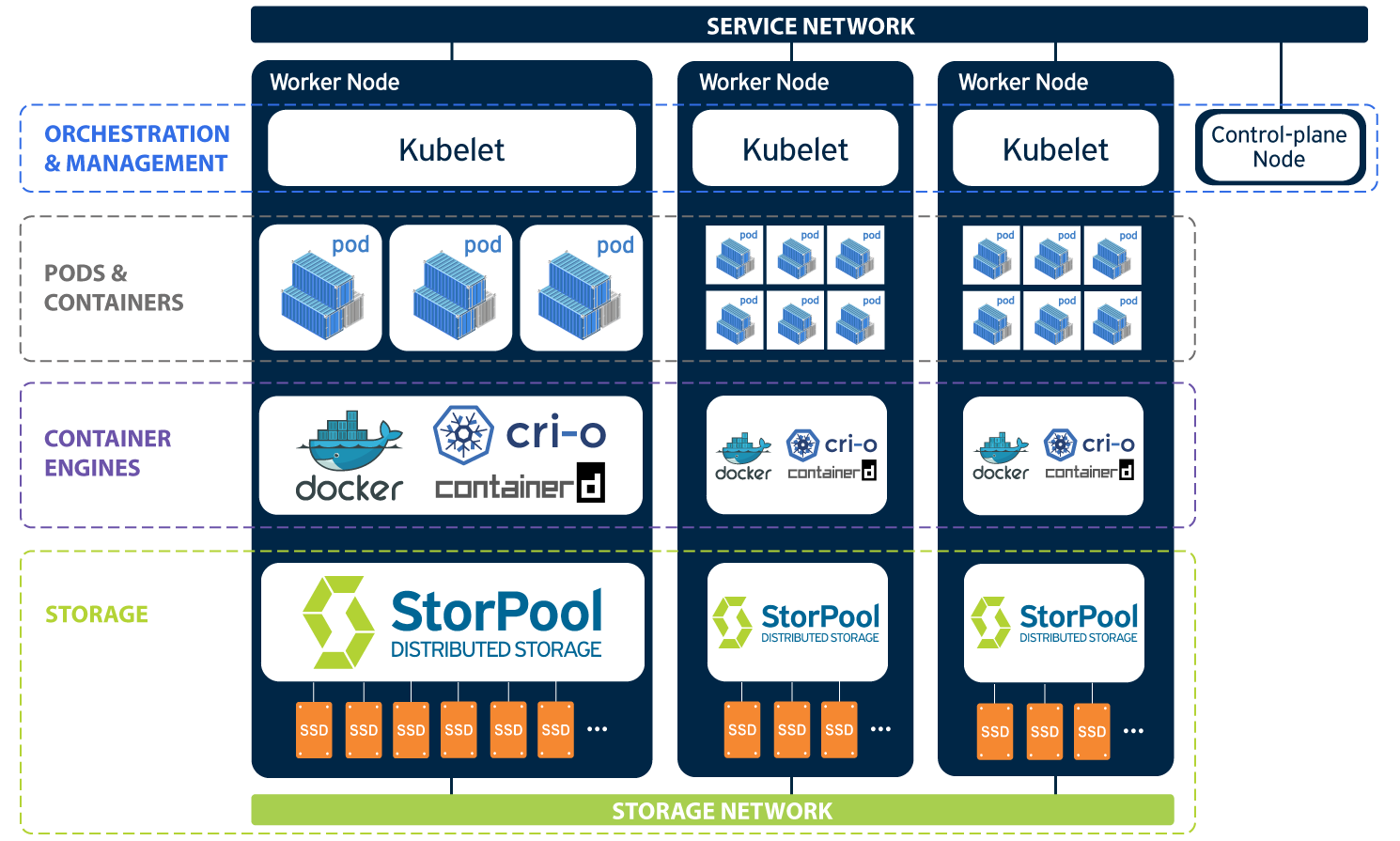
The StorPool CSI driver allows on-premise Kubernetes clusters to use StorPool as persistent storage. It supports dynamic provisioning. Keep in mind that the StorPool integration is designed for bare-metal servers. If you want to run the Kubernetes cluster in a virtualized environment then the cloud management software (say OpenStack or VMware) should take care for attaching/detaching volumes to the VMs.
Further, our integration provides persistent volumes to K8S that are stored in the StorPool cluster and can be dynamically attached/detached to different Kubernetes nodes as needed (either VMs or bare metal hosts, that run the containers), and it is block-level storage. StorPool (on bare metal) supports persistent volume claims in ReadWriteOnce or ReadOnlyMany, like most block device drivers – iSCSI, Amazon EBS, rbd, etc. For ReadWriteMany pretty much the only option seems to be NFS.
Benefits of Using Persistant Storage for Kubernetes
Kubernetes Persistent Storage And Mixing other IT Stacks
In addition to providing persistent volumes for Kubernetes, StorPool also supports multiple IT stacks. It can provide persistent shared storage – from one storage system – to several IT stacks (IT infrastructure platforms). The list of supported cloud orchestration systems is one of the widest in the industry and includes OpenStack, VMware, Hyper-V, OnApp, OpenNebula, CloudStack, and proprietary Cloud Management Systems.
Learn more about the integration in our paper“Persistent Storage for Kubernetes with StorPool”!
Use Cases and Usage
Many of our MSP clients provide managed services to their customers. A recent example is a managed database service that looks similar to Amazon RDS. This is achieved by using Kubernetes with the Percona or KubeDB database operators. The solution is built on MSP’s own infrastructure so their Kubernetes cluster is integrated with each underlying subsystem, one of which is the storage provider StorPool.
StorPool has native integration with Kubernetes (introduced in StorPool’s v18.02 release) through which persistent volumes are provided to the pods. The setup consists of an operational StorPool storage cluster, redundant network layer, and a number of bare metal Kubernetes nodes with StorPool client (initiator) installed. Each Kubernetes persistent volume is backed by a StorPool volume attached as a block device to the node where the pod, which requested it, is running.


Container Challenges
Containers emerged as a way to make software portable. The container contains all the packages you need to run a service. The provided isolation makes containers extremely portable and easy to use in development. A container can be moved from development to test or production with no or relatively few configuration changes.
Historically Kubernetes was suitable only for stateless services. However, all applications work with data, which requires persistence, which leads to the creation of persistent storage for Kubernetes. Implementing persistent storage for containers is one of the top challenges of Kubernetes administrators, DevOps and cloud engineers. Containers may be ephemeral, but more and more of their data is not, so you need to ensure its survival in case of container deletion or hardware failure.