How it works
Remarkable Data Storage Software by StorPool
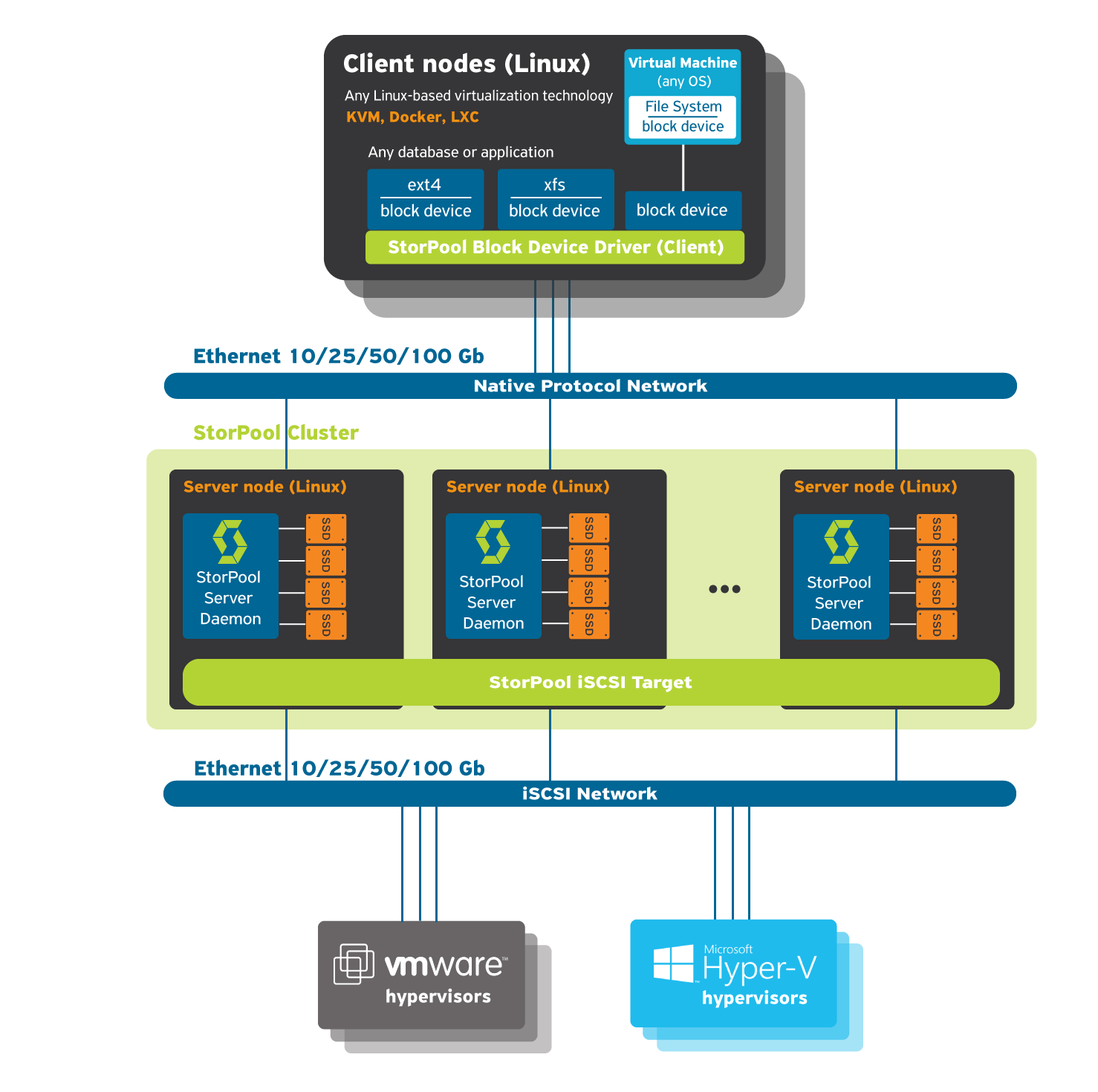
StorPool is a next-generation data storage software. It pools the capacity and performance of attached local DAS devices (NVMe, SSD, HDD), from multiple standard servers, to create a single pool of shared block storage. StorPool works on a cluster of servers in a fully distributed, shared-nothing architecture. All functions are performed by all servers on an equal peer basis. It works on standard servers running GNU/Linux.
StorPool software consists of two parts – a storage server (target) and a storage client (driver, initiator) that are installed on each physical server (host, node). Each host can be a storage server, a storage client, or both (i.e. a converged set up/ converged infrastructure). To storage clients, StorPool volumes appear as local block devices under /dev/storpool/*. Data on volumes can be read and written by all clients simultaneously and consistency is guaranteed through a synchronous replication protocol. The StorPool client communicates in parallel with the StorPool servers. StorPool extends support to other operating systems/hypervisors as clients of the StorPool storage system through a scale-out and highly available iSCSI target developed for this purpose.
StorPool provides standard block devices. One or more volumes can be created through the StorPool JSON API or CLI volume manager. Redundancy is provided by multiple copies (replicas) of the data, written synchronously across the cluster. Users can set the desired number of replication copies.
StorPool provides a very high degree of flexibility in volume management. Every disk that is added to a StorPool cluster adds capacity to the cluster, not just for new data, but also for existing data. StorPool does not impose any strict hierarchical storage structure that links and reflects to the underlying disks. It simply creates a single pool of data storage (global namespace), that utilises the full capacity and performance of a set of commodity drives.
In StorPool, redundancy is guaranteed through a synchronous replication algorithm. This can be thought of as a very advanced software RAID between servers and racks. Consistency is guaranteed by end-to-end data integrity checks. Typically, data needed by one StorPool Client is located on drives, which are located in all servers in the cluster. This layout provides high performance and real-time load balancing. Data placement and replication is independently selectable for each volume.
StorPool supports various other hypervisors, including VMware vSphere/ESX/ESXi, Windows Server, Hyper-V and others. These hypervisors access StorPool’s shared storage service through the iSCSI protocol. This approach offers a high level of compatibility with every system that supports iSCSI. As this is an early implementation, StorPool cannot yet run in a hyper-converged configuration with these operating systems/hypervisors.
Currently StorPool has native support for Linux with KVM, LXC, LVM, Docker and any other technology compatible with the Linux storage stack, and appears as a standard SAN to other hypervisors/operating systems. StorPool is integrated with OpenStack, CloudStack, OpenNebula and supports OnApp, libvirt and Proxmox as well as custom cloud management solutions. It is compatible with many file systems, such as ext4 and XFS file systems, and with any system designed to work with a block device, e.g. databases and cluster file systems like OCFS and GFS. In the case of VMware/Windows, StorPool appears as one large block and is formatted with VMFS, NTFS or FAT.
What Makes StorPool a Better Data Storage Solution?
This simple answer is: StorPool just works. It’s fast. Reliable. Delivers on what it promises.
StorPool is a direct replacement for traditional SAN storage boxes, all–flash arrays and other storage software. It provides highly reliable, scalable, high-performance block storage, built out of standard x86 servers. The data is “sliced”, and copies are distributed between a chosen number of servers or racks. This provides high levels of reliability, speed and fast recovery times.
Further, StorPool enables the implementation of converged/integrated infrastructure solutions, known as hyper-convergence. Users can run compute (virtual machines, applications, databases, etc.), on the same servers as the storage (StorPool). This is because StorPool is highly efficient, taking just 5-10% of the resources of each server and leaving the majority of resources available for running apps. This convergence of storage and compute loads allows customers to increase levels of utilization, thus significantly reducing Total Cost of Ownership (TCO), and therefore boost Return on Investment (ROI).
Read more on Advantages