
The capable CloudStack storage solutions are few. Cloud providers, MSPs, and Enterprises benefit from StorPool together with CloudStack in order to accelerate their applications while increasing the ROI (Return on Investment) of their IT. Combined with its efficiency, scalability, and reliability, StorPool can boost the performance of your CloudStack infrastructure and help you to achieve superb end-user experience.
The History of Building StorPool’s integration with CloudStack
StorPool decided to do its CloudStack integration about two years ago. Back then, the main goal in mind was to expose all the functionality in the storage system and also map StorPool concepts to CloudStack concepts. This was necessary since there is no standard of how things are made or how they behave. A clear example of that is the concept of snapshots in CloudStack and OpenStack – being rather different from each other.
We first did the deployment only with the KVM hypervisor. And tried to make the integration behave similarly to other primary storage backends for KVM, that already exist. The reason for that is so that StorPool can behave in a similar manner and the customer could still feel comfortable and confident using it. This all started back in 2016 when a customer asked about the possibility of using StorPool with CloudStack. The environment was fully brought up in just two weeks, after which the StorPool-CloudStack integration was born. However, the above-mentioned customer then decided to go with a different cloud management system, which led to the integration “sitting on the shelf” until earlier this year. That’s when we rebooted our marketing efforts and our first production deployments with CloudStack.
How does StorPool’s CloudStack storage solution work?
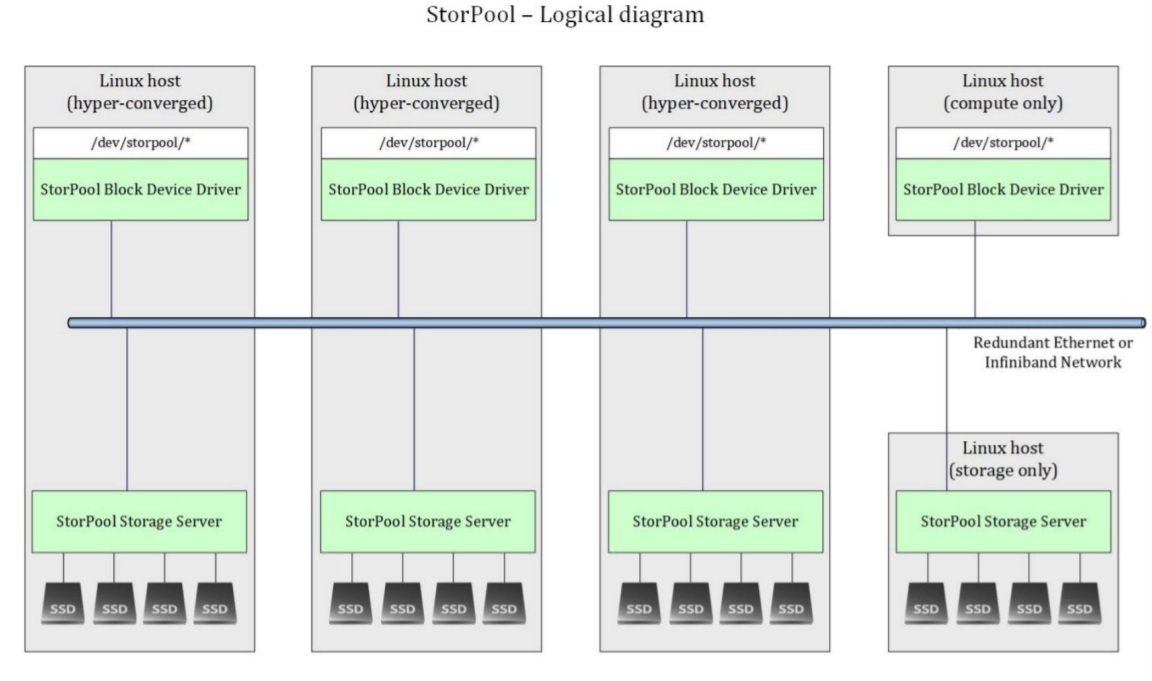
You can think of it as having a control plane and a data plane.
On the data plane, on each host shown above, there are virtual machines, which are presented with raw disk images. Virtual disks correspond to block devices in the host, in this case, the block devices are provided by a StorPool Block Device Driver. The StorPool Block Device Driver knows where in the cluster the data is and it communicates to the StorPool servers directly. There is no hopping between nodes to get to the data and there are no blocking metadata requests. Metadata (the map of where data is in the cluster) is propagated to the initiator (driver) ahead of time.
StorPool to CloudStack integration is on the control plane. This means that when CloudStack needs to create a volume, it does a StorPool API call. When CloudStack needs to attach a storage volume to a host, it does an API call to StorPool, etc.
The data plane, on the other hand, is completely independent. For it to be set up you need a StorPool Block Device Driver in the host in order to be able to process reads and writes, etc. Additionally, the data plane has all the performance critical aspects of the storage solution such as using RDMA in the network interface cards, doing a kernel bypass.
StorPool’s CloudStack Storage Plugin functionality
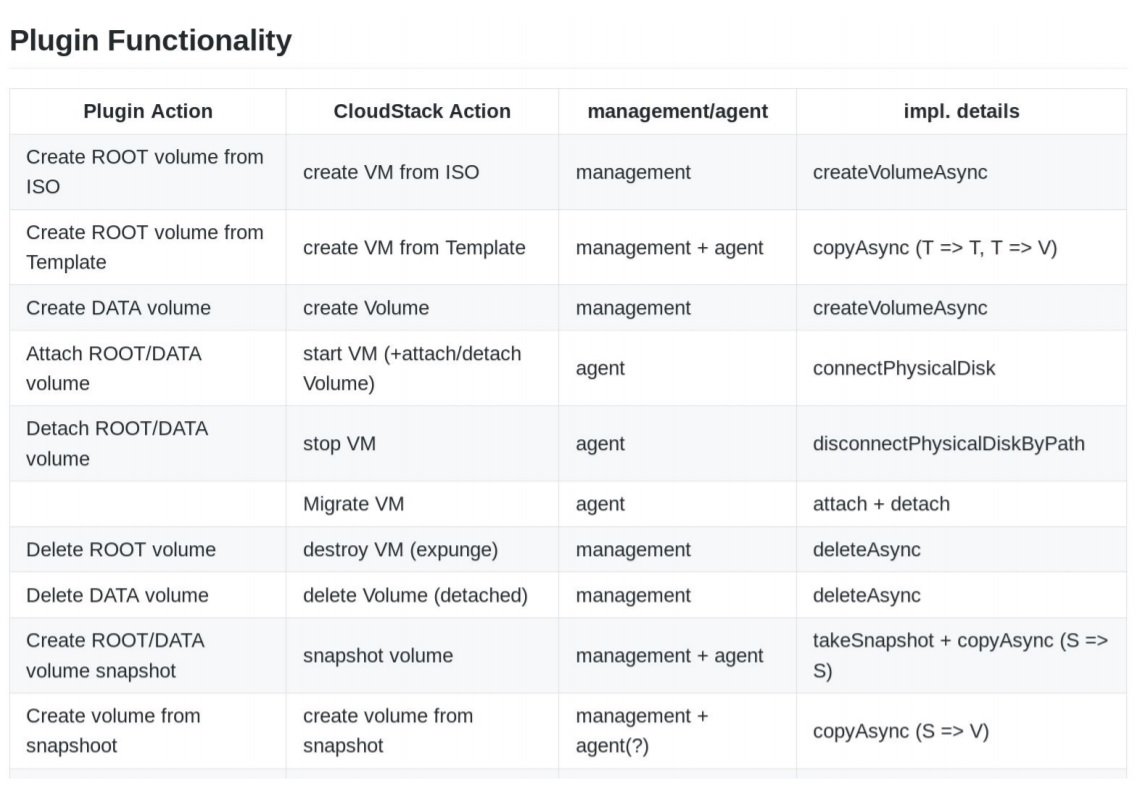
When first building the integration StorPool mapped out all the high-level functionality. We mapped everything, that a customer would want to do in the CloudStack UI to the Function call in the StorPool plugin.
So for example, if you go to the CloudStack UI and you request to create a ROOT volume from ISO, in the StorPool plugin that command would correspond to a call called “createVolumeAsync”.
And in another example, in order to live-migrate, a virtual machine from one host to another, on the storage backend the virtual disks of the said virtual machine are attached to the new hypervisor. The virtual machine is being migrated and afterward, the virtual disks on the old hypervisor are detached.
The Cloudstack/KVM/iSCSI patch

Back in 2016 when first CloudStack integration was being done, the only hiccups, that StorPool had was in the CloudStack’s iSCSI driver. There if you have multiple storage backends – iSCSI, StorPool, etc. when a volume is detached, the iSCSI driver instead of failing and returning the error, that it is in fact not a block device, which is managed by the iSCSI driver. What it does is that it says the volume has been detached successfully.
The roadmap
In terms of roadmap, StorPool has plans to further develop its CloudStack storage integration and work on the following features:
- Expose StorPool’s QoS functionality through CloudStack – we would expose QoS in a way similar to how the SolidFire driver for CloudStack exposes QoS parameters.
- Expose StorPool snapshots and StorPool multi-site capabilities through the new backup service – With StorPool you can have multiple clusters in different locations. And also create a snapshot in one cluster and send it to another cluster. Customers often use this functionality for backup and disaster recovery. Exposing it through CloudStack makes sense.
- Implement storage migration between StorPool templates and/or between StorPool and non-StorPool storage
If you want to hear the entire talk by Boyan Krosnov and learn more about StorPool’s integration with CloudStack, click the link below.
If you have any questions feel free to contact us at info@storpool.slm.dev