For StorPool, it’s a never-ending mission to provide the best software-defined block storage on the market. We are really excited to be featured on Architecting IT. In this series of posts, you’ll learn more about StorPool’s technology, with a hands-on and in-depth look at how the distributed storage architecture works, how it performs, and how it integrates into an on-premises public cloud strategy.
StorPool’s review on Architecting IT
The StorPool platform is a distributed, scale-out storage solution that uses commodity resources and standard server hardware. The software runs on the Linux operating system, aggregating physical HDD and SSDs into a storage pool that can be presented to either storage nodes in the cluster, client-only nodes, or to other operating systems through the iSCSI protocol.
A StorPool cluster is an ideal solution for providing persistent block-based storage resources to servers running any of the platforms described, as well as traditional VMware and now containerised applications. This can be in an HCI model, or as a dedicated storage environment.
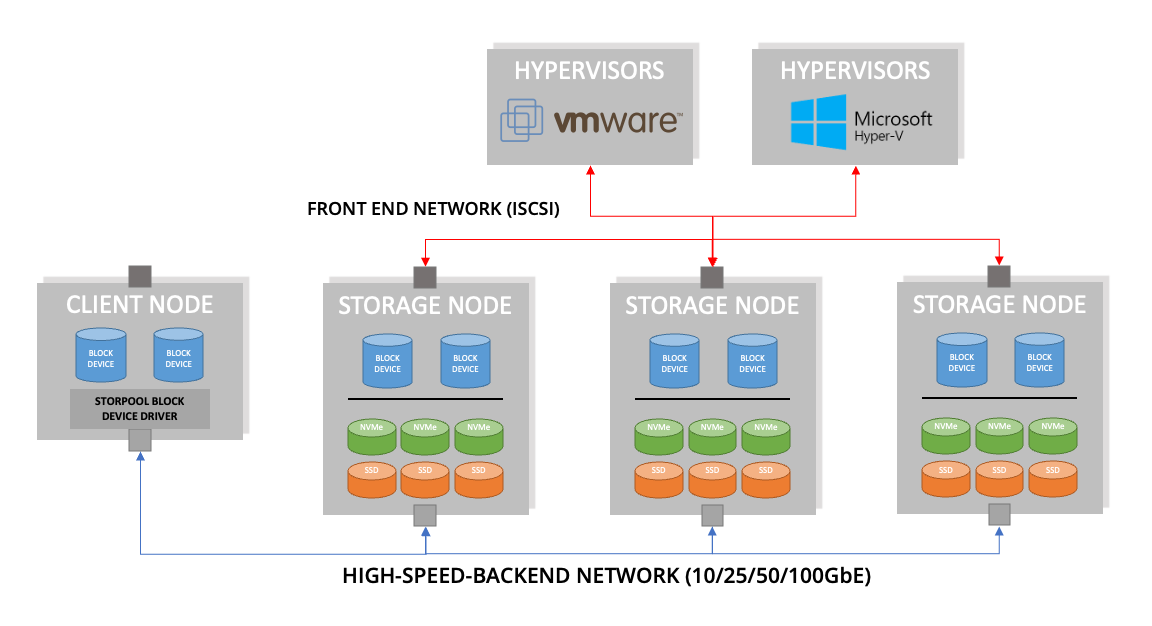
Storage nodes create pools of aggregated storage resources in a “shared-nothing” architecture. Effectively, every node is a peer of each other with distributed management and control. Applications may be run natively on any storage node in a hyper-converged style architecture. Alternatively, the StorPool client device driver enables any Linux server to consume resources from a storage cluster, without needing to provide physical storage capacity. Non-Linux hosts, including Windows and traditional hypervisors are supported through iSCSI on the front-end network as described earlier.
On-Disk Structures and Data Resiliency
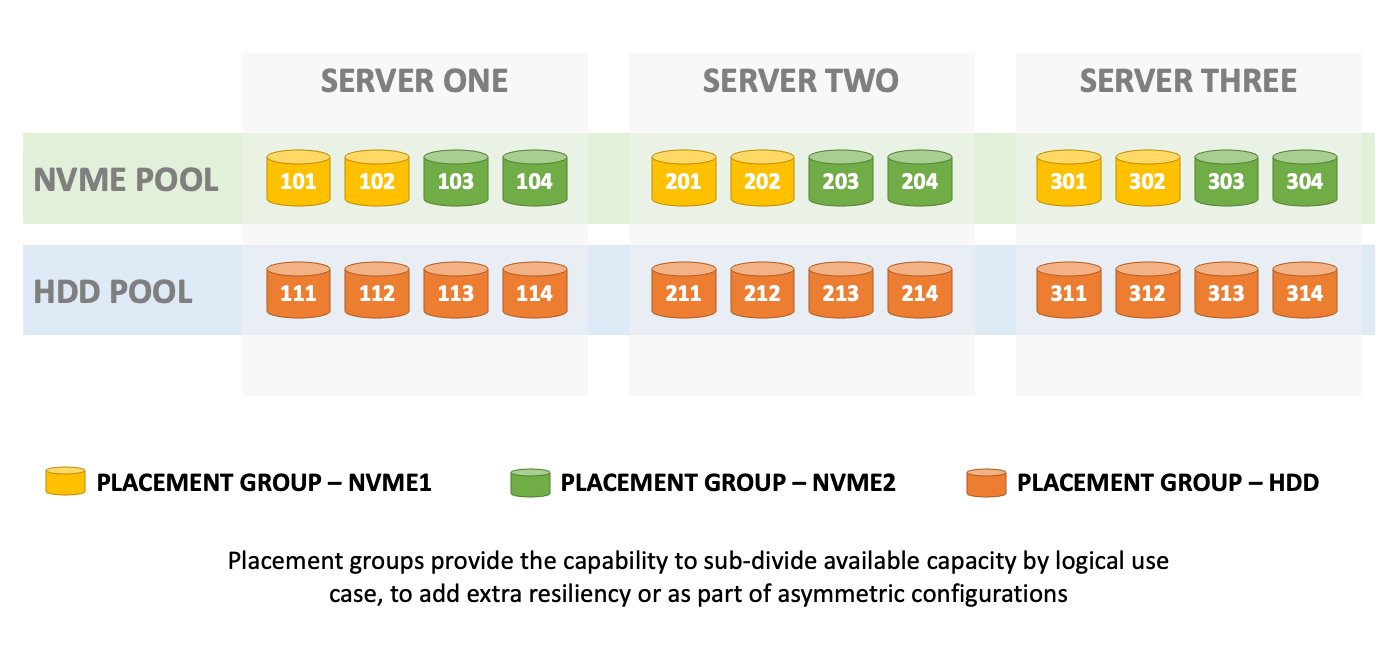
StorPool is a block-storage solution that aggregates and virtualises physical storage resources across multiple nodes or servers. Each server has one or more local drives, which can be NVMe, SSD or HDDs. Each drive (or portions of larger drives) is mapped to a placement group, which is effectively a pool of disks. In our example, we’re showing drives mapped to a single placement group, but this isn’t a requirement. Placement Groups can have a many->one relationship with each piece of physical media.