
Hyper-Converged Infrastructure (HCI) is gaining more ground as the preferred way to build efficient IT infrastructure. In this architecture both the storage and the compute workloads (virtual machines, containers, apps, databases) run on the same physical servers. The promise of HCI is that you would be able to fully utilize your hardware without sacrificing performance. Most HCI deployments struggle to deliver on this promise because of low performance and high resource utilization of the storage system. So it is essential to use a storage system which is simultaneously lightweight, efficient, and extremely fast.
Recently, we worked with a customer with a requirement for building a super-fast, hosted VDI solution, with high utilization. The deployment architecture was hyper-converged to achieve the best possible rack density and unit economics.
One of the hard requirements of the NVMe-powered VDI Cloud project was very high single thread performance which necessitates the use of CPUs with a relatively small number of high frequency CPU cores. There were 39 servers, each with 12 cores. This means that the cost per GHz of the CPUs was relatively high and available compute power that can be “wasted” on the storage system instead of VMs is limited. The need for an efficient storage software was even more pronounced than usual.
Slow storage would severely impact application performance and user experience. Fast, low-latency storage which uses very little CPU resources was needed.
StorPool utilized just 2 CPU cores and 8 GB RAM per node and delivered a blazing fast storage system, peaking at 6,800,000 IOPS and delivering latency of less than 0.15ms (!) under typical load. This allowed the customer to achieve unmatched performance and efficiency.
You can find the specifications of the system and the metrics of the delivered performance below.
Specification of the tested NVMe-based VDI Cloud solution:
39 hyper-converged servers (nodes), each with:
- 1RU chassis with 2x hot-swap NVMe drive bays
- CPU: 2x Intel Xeon Scalable 6-core CPU
- 2 of 12 cores used for the StorPool storage system
- Memory: 192 GB RAM
- 8 of 192 GB RAM used by StorPool
- Boot drive: M.2 NVMe SSD
- NIC: Mellanox ConnectX-4, dual-port 25G
- Pool drives: 2x Micron 9200 PRO 3.8TB NVMe 1 DWPD
- StorPool version: 18.02
Network/Switches: Two top-of-rack switches. Each node is connected via dual 25GbE with SFP28 passive copper DAC cables.
Total capacity: 300 TB raw = 90.8 TB usable (with 3-way replication, and 10% for Copy on Write on-disk format, checksums and safety).
How we configured the system for the tests:
We performed two sets of tests to demonstrate the system’s capabilities in different use-cases:
– an overall storage performance test, showing the peak performance characteristics of the system
– an IOPS vs. latency test, showing the average latency with a particular level of sustained load
Overall storage performance test specification:
- For the overall storage performance test, we created:
- 39 StorPool volumes, 100GB each, filled with random data
- each volume has triple replication
- The data of each volume is spread across all 78 drives to give each volume the best peak performance and the best resilience against node failures possible.
- one volume attached to each node
Then we initiated a parallel FIO workload:
- a FIO server is started on each server, exposing the attached volume
- a parallel FIO job is initiated from the all 39 FIO servers
- FIO parameters: ioengine=aio, direct=1, randrepeat=0
- Block size – see table
- Queue depth – see table
The results: performance of the system, aggregated (all-initiators):

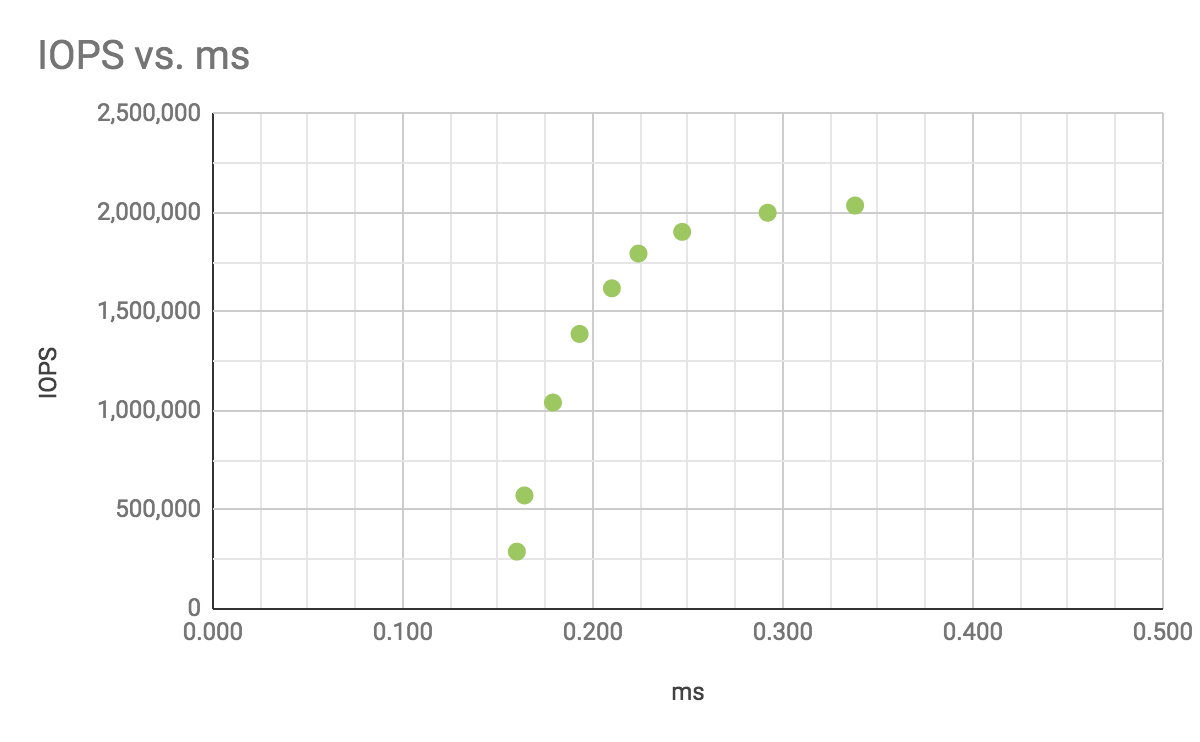
IOPS vs. Latency test specification:
- For the IOPS vs. Latency test, we created:
- one StorPool volume with size of 1TB, pre-filled with random data
- the volume has 3 copies and is striped across all 78 drives
- the volume is attached to all 39 servers
Then we initiated a parallel FIO workload:
- a FIO server is started on each server, exposing the attached volume
- a parallel FIO job is initiated from the all 39 FIO servers
- FIO parameters: ioengine=aio, direct=1, randrepeat=0
- Block size = 4k
- Queue depth = 1, 2, 4, 6, 8, 10, 12, 14, 16 – depending on the test
The results: IOPS vs. Latency, aggregated (all-initiators):

Do you plan to build a hyper-converged storage system? Or you have a NVMe-powered VDI cloud project? Do not hesitate to get in touch with StorPool and find out how to achive astonishing performace of the storage system and your cloud. Write us at info@storpool.slm.dev.