
Performance test report. NVMe-class storage performance in VMs.
Introduction
In this performance test we measured 13.8M IOPS on a 12-node cluster built on standard off-the-shelf Intel servers. This is the highest storage performance reached by an HCI (hyper-converged infrastructure) on the market. We also show that even a small StorPool storage system, with just 48 NVMe drives, can provide millions of IOPS at latencies of a fraction of a millisecond. For real-world applications, microsecond latencies translate to remarkable application responsiveness and performance.
We deliver on the SDS (Software-Defined Storage) promise – extremely fast and highly available shared-storage system, built with standard servers, with rich data services (snapshots/clones, thin provisioning, end-to-end data integrity, multi-site functionality). The results show that with StorPool, a private or public cloud can deliver highly-available VMs with the performance of local NVMe SSDs.
We configured and tested a 12-server KVM hyper-converged system on hardware graciously provided by the Intel®️ Datacenter Builders program. The tests show this 12-node hyper-converged environment delivers 13.8M random read IOPS at
Test results
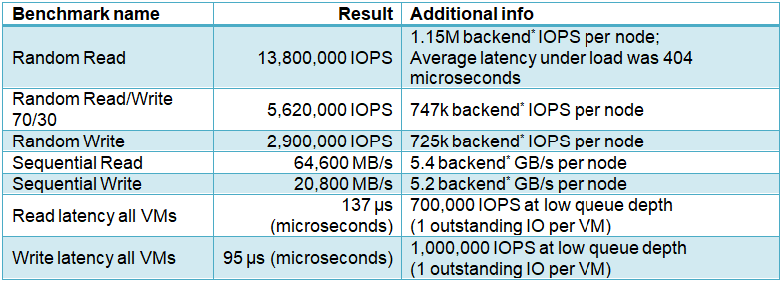
* backend IOPS and backend GB/s calculation estimates load on storage servers and underlying NVMe drives. Write operations are counted 3 times for 3x replication. Read operations are counted as 1 backend operation each. For
These results are exceptional; here is some context to better understand them.
In this 12-node StorPool-powered hyper-converged set-up we run 96 VMs, each executing a single FIO job. From just 48 NVMe drives, StorPool delivers 143,000 IOPS per VM simultaneously to 96 VMs. This performance is well above typical requirements, so a cloud using StorPool can safely focus on delivering the best service to their customers, instead of constantly battling with high latencies under load and “noisy neighbors” problems, which are typical for many storage solutions.
In the sequential tests, 64.6 GB/s is equal to 86% of the theoretical network throughput (75GB/s).
In the random read/write tests, 13.8 M IOPS * 4 KiB is equal to 75% of theoretical network throughput. The relatively small number of NVMe drives (48 drives total) is the limiting factor for this benchmark.
There is a performance test by Microsoft on a similar 12-node hardware set-up, titled “The new HCI industry record: 13.7 million IOPS with Windows Server 2019 and Intel® Optane™ DC persistent memory”. In the Microsoft S2D/Hyper-V/Optane test, because of the very small active set (3.0 TB) and caching, almost all storage operations are served from RAM or Optane memory, not from the underlying NVMe storage drives. Storage experts like Chris M Evans call this “cheating”, rightfully so in our opinion. The StorPool system is not only faster, with IO being processed by the actual NVMe drives, but also uses less storage hardware.
The 95 microseconds write latency includes 3 network transfers and 3 NVMe drives committing the write. It is ten times faster than the “sub millisecond” latency advertised by traditional All-Flash arrays. For the first time one can get a shared storage system, as fast as locally attached drives (DAS).
In all tests here, we perform end-to-end data integrity checking (generating, storing and verifying checksums). End-to-end data integrity is crucial to protect the data against hardware and firmware issues, but most storage systems don’t have this functionality.
Description of the environment
The setup consists of 12 servers with identical hardware configuration, provided by the Intel Datacenter Builders Program. Each server is connected using dual 25G Ethernet to an Ethernet switch. In this setup there is a single switch for simplicity. Production-grade environments typically use two switches for redundancy.
The following diagram illustrates the physical topology.
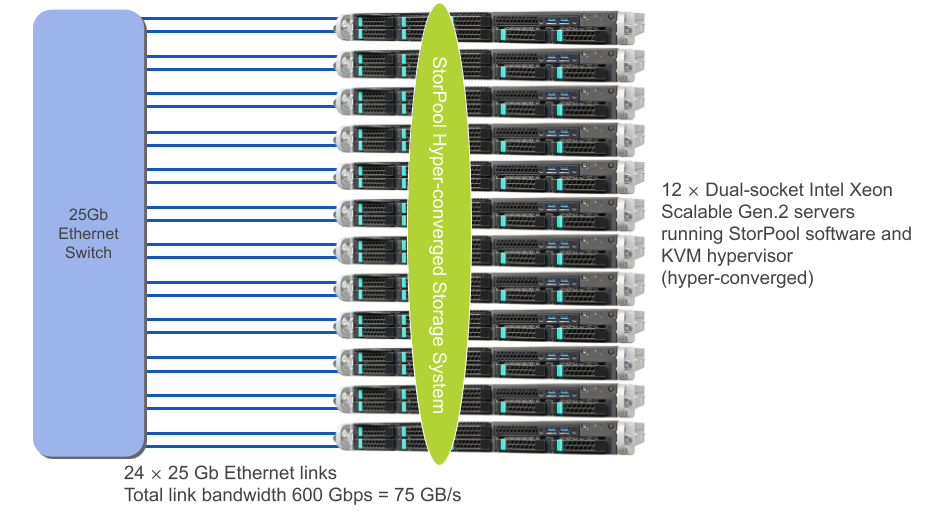
Each of the 12 servers has the following hardware configuration:
- 56 cores / 112 threads (2x Intel 2nd Gen Xeon Scalable CPUs)
- 384 GB RAM (12 x 32 GB RDIMMs)
- 32 TB NVMe (4x Intel P4510 8TB NVMe drives)
- Intel XXV710 dual-port 25G NIC

The software installed on each server is:
- Operating system – CentOS 7.6, Linux kernel 3.10.0-957
- Hypervisor – KVM, libvirt and qemu-kvm-ev from CentOS Virt-SIG
- Storage software (SDS) – StorPool v19
- Storage benchmarking software – FIO
The following diagram illustrates how the hardware and software components inter-operate with each other. For simplicity it shows just one of the 12 servers.
Each host runs 8 VMs, each VM has 4 vCPUs, 1 GiB RAM and a 500 GiB virtual disk on StorPool. VMs are used only for running the benchmark tools.
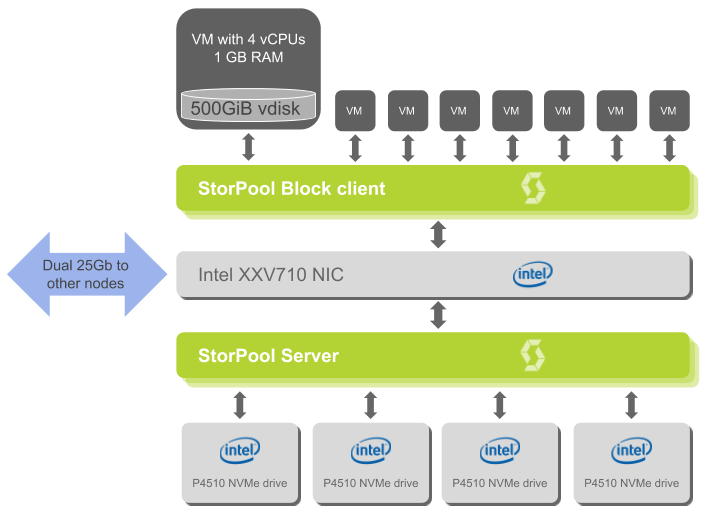
In this test scenario StorPool uses approximately 11% of the total CPU resources. The remaining 89% of the CPU cores are free for running VMs.
To process more than 1M IOPS per node StorPool uses 6 CPU cores (incl. StorPool server, StorPool client).
The following table summarizes CPU usage:

Memory usage:
- 25 GiB per node (6.5%) for StorPool (client and server combined) and
- 359 GiB per node (93.5%) remain available for the Host operating system and VMs
The memory usage for StorPool is small – less than 1GB RAM per 1 TB raw storage, and it’s mostly used for metadata.
Testing methodology
We use the FIO client-server functionality to perform the benchmark.
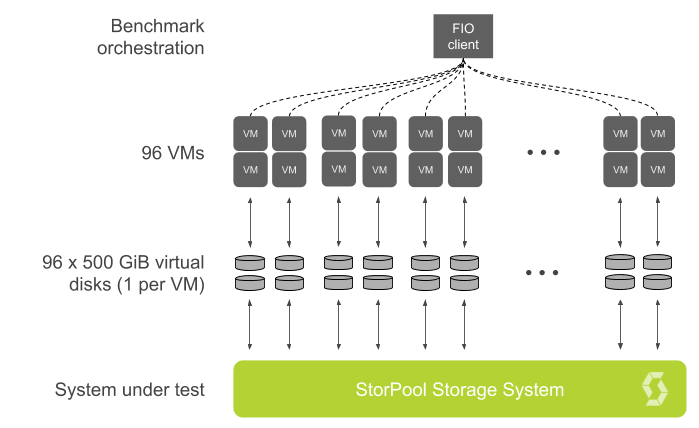
We performed tests designed to measure the performance envelope of the system under test. The performance envelope covers the extremes of the capabilities of a storage system and is sufficient for general characterization of performance.
1. Maximum IOPS
- random
read random read/write- random write
2. Maximum MB/s
- sequential read
- sequential write
3. Minimum latency
- random read with queue depth 1
- random write with queue depth 1
The parameters used for these tests are summarized in the following table:
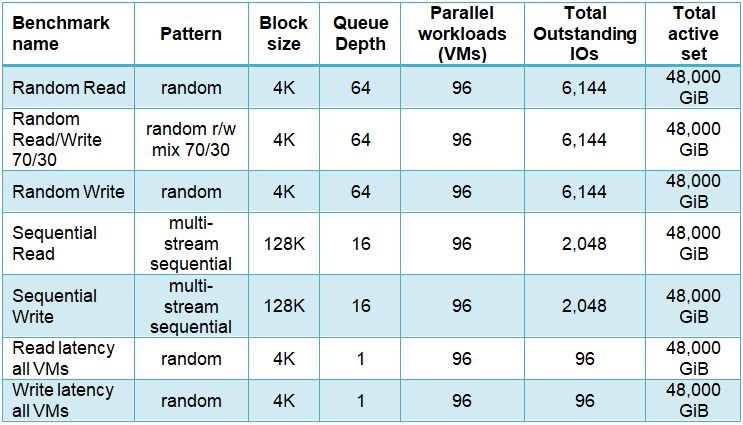
In all tests FIO was configured as follows:
- ioengine=libaio – Use Linux Native Async IO;
- direct=1 – Bypass the guest’s buffer cache;
- randrepeat=0 – Produce a unique random pattern on every run instead of repeating previous random patterns, to avoid cache effects;
- numjobs=1 (default) – Use a single thread for execution.
Quality controls for test results
- No data locality: Data for each VM was specifically placed on non-local drives to avoid any positive skew caused by the data being locally stored.
- No caching: There is no data caching anywhere in the stack. Each read or write operation is processed by the NVMe drives. The number of operations processed by the underlying drives was compared to the number of operations counted by the benchmark tool. The numbers were identical.
- Active set size: The active set was sufficiently large to exclude effects from caching, even if it was used. The 48,000 GiB active set is equal to 44% of system capacity.
- No write buffering: All write operations were submitted by the test tools with a “sync” flag, instructing the storage system to persist them to power-loss protected devices (NVMe drives) before completing the write operations.
- Repeatability and steady state: Tests were run for sufficient duration, such that running them for longer does not influence the result.
- End-to-end measurement: IOPS, MB/s and latency are measured by the test tool (FIO) inside the virtual machines, so the
presentented results are end-to-end (including all overheads across the storage and virtualization stacks)
Why these numbers matter
Storage has been one of the main limiting factors in modern IT. There has always been a trade-off between speed and high availability. Here we prove that with a best-of-breed software-defined storage solution, you can eliminate this trade-off altogether. Having a shared storage system (highly available) with the performance of local NVMe drives is now possible.
By using this technology any public and private cloud builder can deliver unmatched performance for their applications, VMs and containers. If you aim to build a powerful public or private cloud, this solution can permanently solve all your storage performance issues.
If you want to learn more or have any questions, do contact us at info@storpool.slm.dev.